NVIDIA NeMo Inference Microservice Deploy Job
W&BからNVIDIA NeMo Inference Microserviceにモデルアーティファクトをデプロイします。この際、W&B Launchを使用します。W&B LaunchはモデルアーティファクトをNVIDIA NeMoモデルに変換し、稼働中のNIM/Tritonサーバーにデプロイします。
W&B Launchは現在、以下の互換性のあるモデルタイプを受け付けています:
備考
デプロイメントの時間はモデルとマシンのタイプによって異なります。基本のLlama2-7bコンフィグは、GCPの a2-ultragpu-1g で約1分かかります。
クイックスタート
まだ作成していない場合は、Launchキューを作成してください。以下にキューの設定例を示します。
net: host
gpus: all # 特定のGPUセットまたは `all` を指定してすべて使用
runtime: nvidia # また、nvidia container runtimeも必要
volume:
- model-store:/model-store/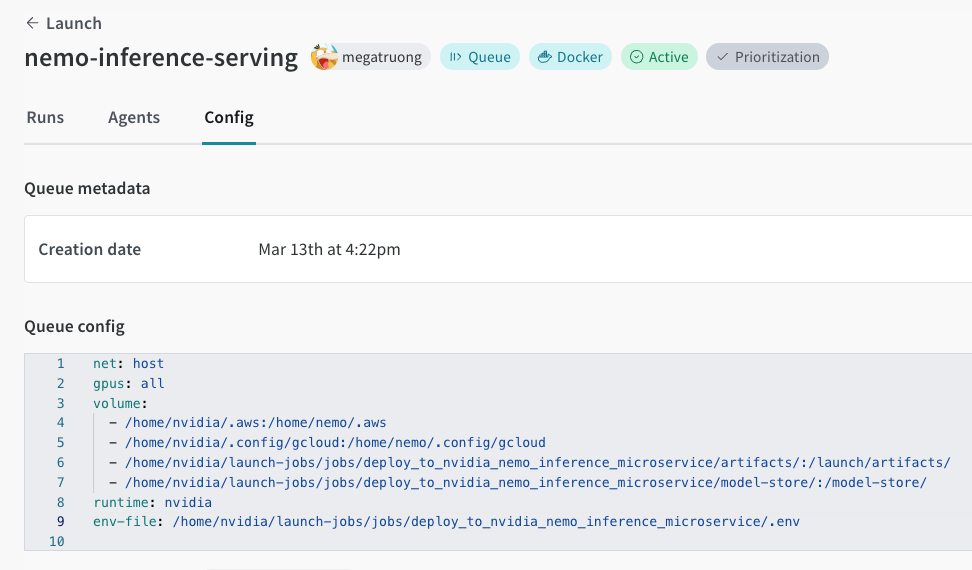
プロジェクトにこのジョブを作成します:
wandb job create -n "deploy-to-nvidia-nemo-inference-microservice" \
-e $ENTITY \
-p $PROJECT \
-E jobs/deploy_to_nvidia_nemo_inference_microservice/job.py \
-g andrew/nim-updates \
git https://github.com/wandb/launch-jobsGPUマシンでエージェントを起動します:
wandb launch-agent -e $ENTITY -p $PROJECT -q $QUEUEお好みの設定でLaunch UIからデプロイメントジョブを提出します。
- CLIからも提出できます:
wandb launch -d gcr.io/playground-111/deploy-to-nemo:latest \
-e $ENTITY \
-p $PROJECT \
-q $QUEUE \
-c $CONFIG_JSON_FNAME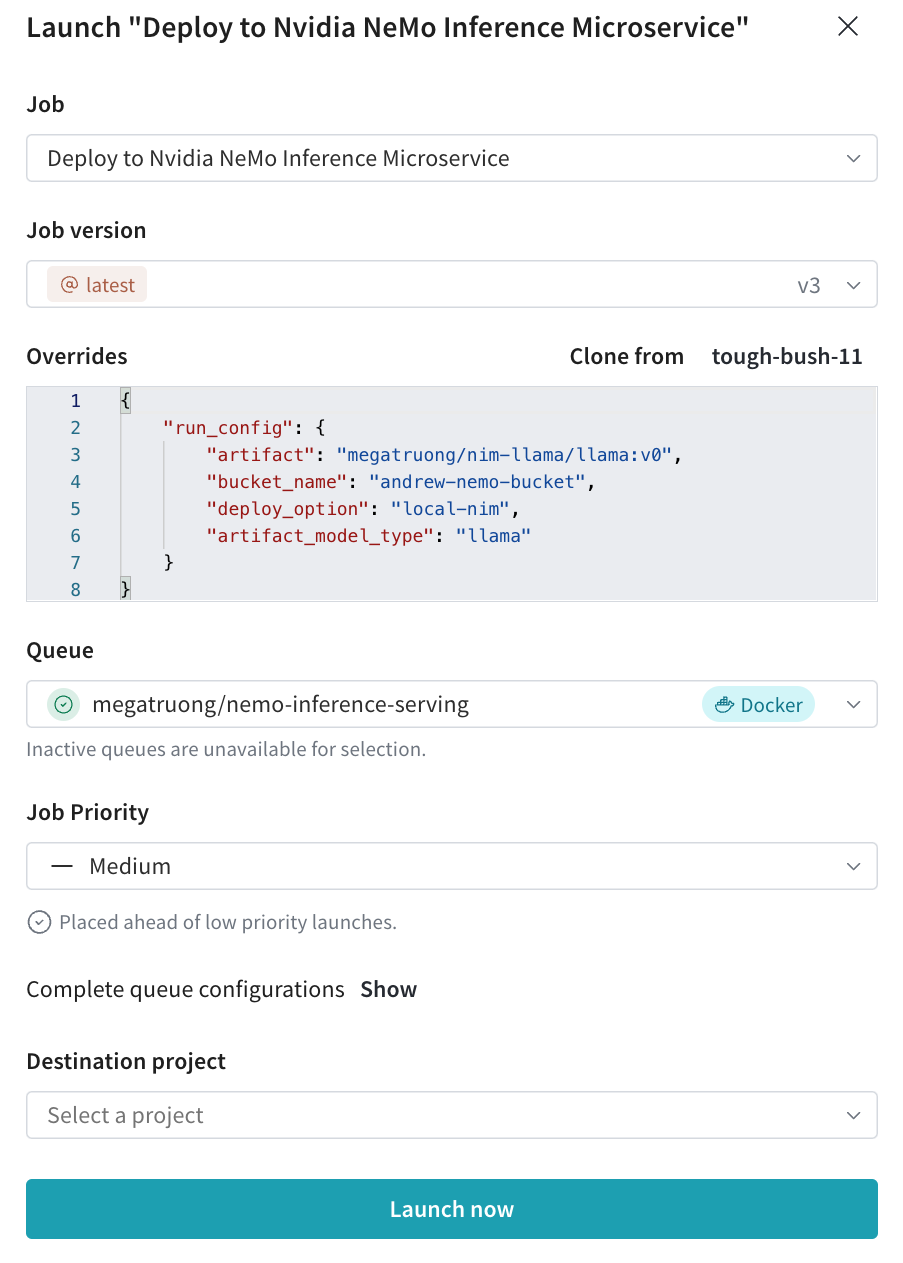
- CLIからも提出できます:
Launch UIでデプロイメントプロセスを追跡できます。
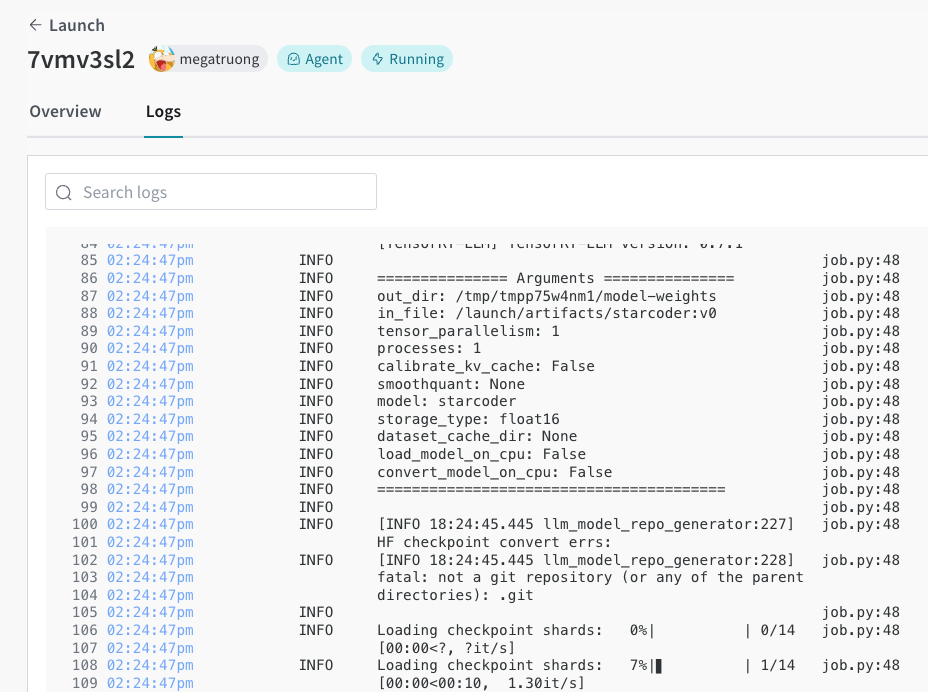
完了したら、エンドポイントにcurlをすぐに実行してモデルをテストできます。モデル名は常に
ensembleです。#!/bin/bash
curl -X POST "http://0.0.0.0:9999/v1/completions" \
-H "accept: application/json" \
-H "Content-Type: application/json" \
-d '{
"model": "ensemble",
"prompt": "Tell me a joke",
"max_tokens": 256,
"temperature": 0.5,
"n": 1,
"stream": false,
"stop": "string",
"frequency_penalty": 0.0
}'