XGBoost Sweeps
Weights & Biases を使用して、機械学習の実験管理、データセットのバージョン管理、プロジェクトの共同作業を行いましょう。
ツリーベースのモデルから最高のパフォーマンスを引き出すためには、適切なハイパーパラメーターの選択が必要です。early_stopping_rounds はいくつに設定するべきですか?ツリーの max_depth はどのくらいにすれば良いでしょうか?
最も性能の良いモデルを見つけるために高次元のハイパーパラメーター空間を検索することは、すぐに手に負えなくなる可能性があります。ハイパーパラメータ探索はモデル同士のバトルロワイヤルを整理し効率的に実行する方法を提供します。自動的にハイパーパラメーターの組み合わせを検索して、最も最適な値を見つけます。
このチュートリアルでは、Weights & Biases を使用して XGBoost モデルで高度なハイパーパラメータ探索を実行する方法を、3つの簡単なステップで紹介します。
以下のプロットで概要を確認できます:
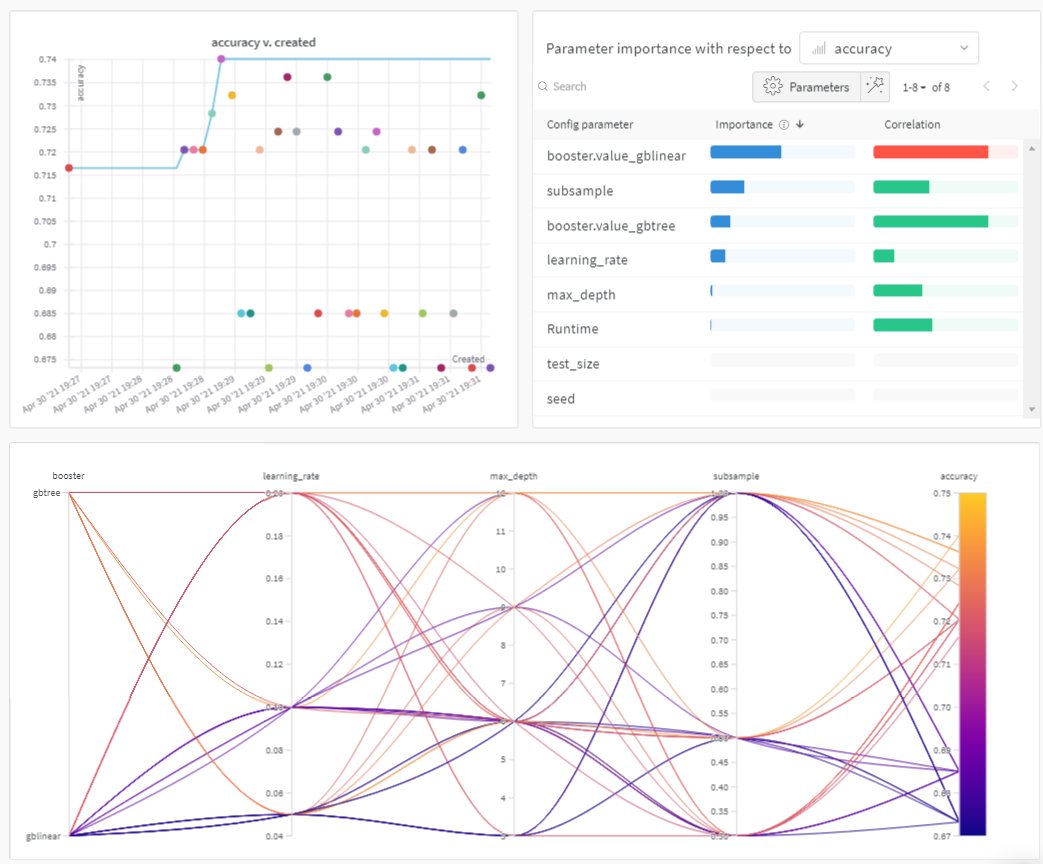
Sweeps: 概要
Weights & Biases でハイパーパラメーター探索を実行するのは非常に簡単です。たった3つのシンプルなステップだけです:
探索の定義: 探索を定義する辞書のようなオブジェクトを作成します。どのパラメータを検索するか、どの探索戦略を使用するか、どのメトリクスを最適化するかを指定します。
探索の初期化: コード1行で探索を初期化し、探索設定の辞書を渡します:
sweep_id = wandb.sweep(sweep_config)探索エージェントの実行: こちらもコード1行で実行します:
wandb.agent()を呼び出し、sweep_idとモデルアーキテクチャとトレーニングを定義する関数を渡します:wandb.agent(sweep_id, function=train)
以上です!これでハイパーパラメーター探索の実行は完了です!
以下のノートブックでは、これらのステップをさらに詳しく説明します。
このノートブックをフォークし、パラメータを調整したり、自分のデータセットでモデルを試してみることを強くお勧めします!
リソース
!pip install wandb -qU
import wandb
wandb.login()
1. 探索の定義
Weights & Biases の Sweeps を使えば、わずか数行のコードで探索を思い通りに設定できます。探索設定は辞書や YAML ファイルとして定義できます。
いくつかの項目を一緒に見てみましょう:
- Metric – 探索が最適化を試みるメトリクスです。このメトリクスは、トレーニングスクリプトによってログに記録される名前 (
name) と、最大化または最小化の目標 (goal) を持つことができます。 - Search Strategy –
"method"キーを使って指定します。Sweep では、いくつかの異なる探索戦略をサポートしています。- Grid Search – すべてのハイパーパラメーターの組み合わせを試みます。
- Random Search – ランダムに選ばれたハイパーパラメーターの組み合わせを試みます。
- Bayesian Search – ハイパーパラメーターとメトリクスのスコアの確率をマッピングする確率モデルを作成し、メトリクスを改善する高い確率のパラメーターを選びます。ベイズ最適化の目的は、ハイパーパラメーターの値を選ぶために時間をかけることですが、その過程で試すハイパーパラメーターの値が少なくなることを意味します。
- Parameters – ハイパーパラメーターの名前を含む辞書で、各イテレーションでその値を引くための離散値、範囲、または分布が含まれます。
すべての設定オプションのリストはこちらで確認できます。
sweep_config = {
"method": "random", # grid または random を試す
"metric": {
"name": "accuracy",
"goal": "maximize"
},
"parameters": {
"booster": {
"values": ["gbtree","gblinear"]
},
"max_depth": {
"values": [3, 6, 9, 12]
},
"learning_rate": {
"values": [0.1, 0.05, 0.2]
},
"subsample": {
"values": [1, 0.5, 0.3]
}
}
}
2. 探索の初期化
wandb.sweep を呼び出すと、探索コントローラーが開始されます。探索コントローラーは parameters の設定を問い合わせるすべてのプロセスに提供し、それらのプロセスから metrics のパフォーマンスを wandb ログを通じて返すことを期待します。
sweep_id = wandb.sweep(sweep_config, project="XGBoost-sweeps")
トレーニングプロセスの定義
探索を実行する前に、モデルを作成してトレーニングする関数を定義する必要があります。この関数はハイパーパラメーターの値を受け取り、メトリクスを出力します。
また、wandbをスクリプトに統合する必要があります。以下の3つの主要なコンポーネントがあります:
wandb.init()– 新しい W&B Run を初期化します。それぞれの Run はトレーニングスクリプトの一回の実行です。wandb.config– すべてのハイパーパラメーターを設定オブジェクトに保存します。これにより、アプリ でハイパーパラメーターの値ごとに実行をソートおよび比較できます。wandb.log()– メトリクスやカスタムオブジェクト(画像、ビデオ、オーディオファイル、HTML、プロット、ポイントクラウドなど)をログに記録します。
また、データのダウンロードが必要です:
!wget https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv
# Pima Indians データセット用の XGBoost モデル
from numpy import loadtxt
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# データの読み込み
def train():
config_defaults = {
"booster": "gbtree",
"max_depth": 3,
"learning_rate": 0.1,
"subsample": 1,
"seed": 117,
"test_size": 0.33,
}
wandb.init(config=config_defaults) # デフォルト設定は探索中に上書きされます
config = wandb.config
# データの読み込み、予測変数とターゲットに分割
dataset = loadtxt("pima-indians-diabetes.data.csv", delimiter=",")
X, Y = dataset[:, :8], dataset[:, 8]
# トレーニングセットとテストセットにデータを分割
X_train, X_test, y_train, y_test = train_test_split(X, Y,
test_size=config.test_size,
random_state=config.seed)
# トレーニングデータでモデルをフィッティング
model = XGBClassifier(booster=config.booster, max_depth=config.max_depth,
learning_rate=config.learning_rate, subsample=config.subsample)
model.fit(X_train, y_train)
# テストデータで予測を行う
y_pred = model.predict(X_test)
predictions = [round(value) for value in y_pred]
# 予測を評価
accuracy = accuracy_score(y_test, predictions)
print(f"Accuracy: {accuracy:.0%}")
wandb.log({"accuracy": accuracy})
3. エージェントによる探索の実行
次に、wandb.agentを呼び出して探索を開始します。
wandb.agent は、W&B にログインしている任意のマシンで実行できます。
sweep_id- データセットと
train関数
これらが揃っていれば、そのマシンは探索に参加します!
Note:
randomスイープはデフォルトで無限に実行されますが、 パラメーターの組み合わせを新たに試し続けます。 アプリの UI からスイープを停止するまで。 実行したいエージェントの総数をcountで提供することでこれを防ぐことができます。
wandb.agent(sweep_id, train, count=25)
結果の可視化
探索が終了したら、結果を確認しましょう。
Weights & Biases は自動で多くの便利なプロットを生成します。
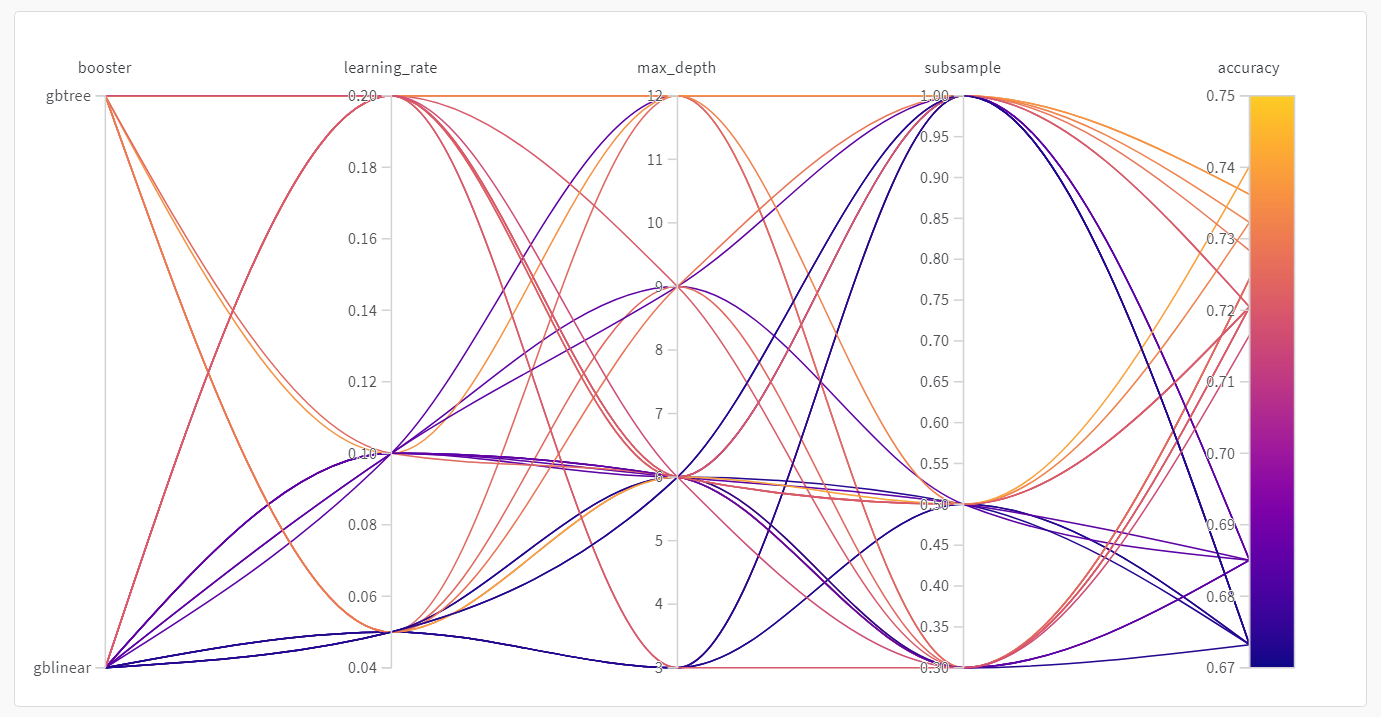
パラレルコーディネートプロット
このプロットはハイパーパラメーターの値をモデルのメトリクスにマッピングします。最も良いモデルパフォーマンスにつながったハイパーパラメーターの組み合わせに絞り込むのに役立ちます。
このプロットを見ると、ツリーを学習器として使用することで若干ですが高い性能が得られることが示唆されていますが、シンプルな線形モデルを学習器として使用するよりも飛び抜けた性能向上ではありません。
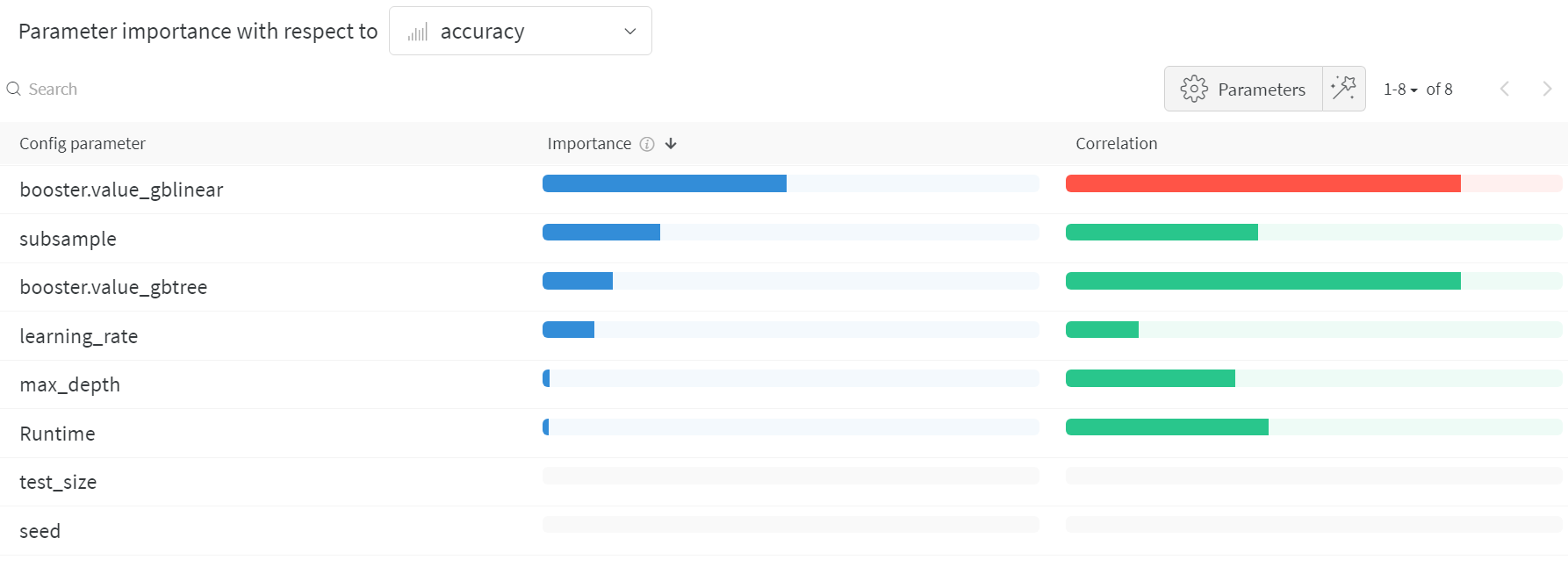
ハイパーパラメーターの重要性プロット
ハイパーパラメーターの重要性プロットは、メトリクスに対して最も大きな影響を与えたハイパーパラメーターの値を示しています。
相関(線形予測子として扱う)と特徴の重要性(結果を元にランダムフォレストをトレーニングした後)を報告するので、どのパラメーターが最も大きな効果を持ち、その効果が正のものであるか負のものであるかを確認できます。
このチャートを読むと、上記のパラレルコーディネートチャートで見た傾向が定量的に確認でき、gblinear 学習器よりも gbtree 学習器の方が一般的に性能が低いことが分かります。
これらの可視化により、最も重要であり、さらに探求する価値があるパラメーター(および値の範囲)に絞り込むことで、費用のかかるハイパーパラメーター最適化の実行に要する時間とリソースを節約できます。